How Lycana's Flare Prediction Got Smarter (Without Getting Greedy)
We caught our ML model overfitting on limited patient data and rewrote the prediction pipeline. Here's what we changed, why it matters, and what the results look like.
Lycana's flare risk score is the feature that matters most. It takes your symptoms, wearable data, weather, and personal history and tries to answer one question: is a flare coming in the next 48 hours?
Last week we shipped three connected changes to the on-device model that powers that score. They all started from the same uncomfortable observation: with only 20–30 days of personal data and 42 input features, the model was learning to fit noise faster than it was learning to recognize flares.
This is the "too few examples per feature" trap — textbook overfitting — and it was quietly inflating our validation scores without actually helping anyone.
We Caught the Overfitting — And Why It Was Hiding
Two things were masking how bad it was.
First, a temporal data leak in the train/validation split. Time-series models have to train on the past and validate on the future. Our old split was position-based, but the examples were not sorted by date, so sometimes "future" data ended up in the training set. The model had already seen the answers — so validation F1 and AUC scores looked great while real-world accuracy was worse. The fix was one line: sort by date before splitting. The payoff is that validation metrics now actually mean what they claim.
Second, 42 features fighting over 20 training examples. At that ratio — roughly 0.5 examples per feature — even a regularized logistic regression can memorize its way to a high training-set score. You cannot tell if the model learned something real or just memorized your week.
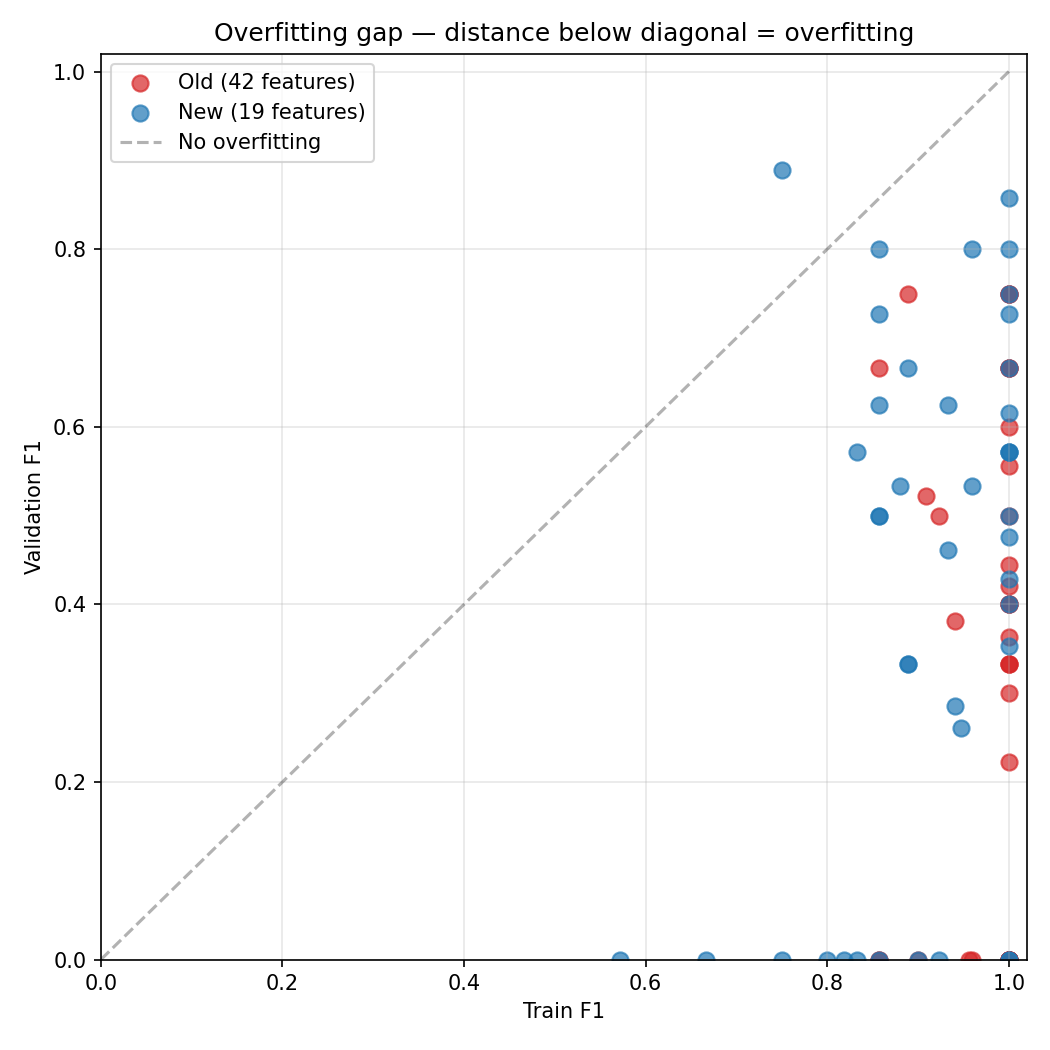
The scatter plot below makes this visible. Each dot is one patient's model. The x-axis is training F1, the y-axis is validation F1. Points below the diagonal are overfitting — high training scores, low validation scores. The old 42-feature model (red) clusters far below the line. The new 19-feature model (blue) sits closer to it.
We Halved the Feature Set
We cut the model input from 42 features to 19. Every cut had a clinical reason.
Lab markers went from 6 to 0 in the ML model. Labs come every 3–6 months. The ML model predicts a 48-hour window. That temporal mismatch means stale labs add noise without predictive value. They still feed the heuristic scoring engine at full weight — they are too important to drop entirely, just wrong for the ML model's time horizon.
Wearable 7-day averages went from 14 to 7. Rolling averages smooth out the very thing we are trying to catch: single-day spikes. We kept z-scores — how much today deviates from your personal baseline — and dropped the averages. We also dropped deep/REM sleep ratios because consumer wearables are too noisy to extract reliable signal from those.
Symptom averages went from 13 to 8. Same reasoning. We kept the latest values and cut redundant 7-day averages that were smearing acute days into unremarkable weeks.
Weather went from 5 to 2. We dropped a temperature deviation feature that was using a hardcoded 20°C fallback when weather data was missing — a bug dressed as a feature. Kept current UV index and an availability flag.
Cyclical time encoding (2 features) was removed entirely. Day-of-week sine/cosine features with zero clinical evidence that Tuesdays flare differently from Fridays.
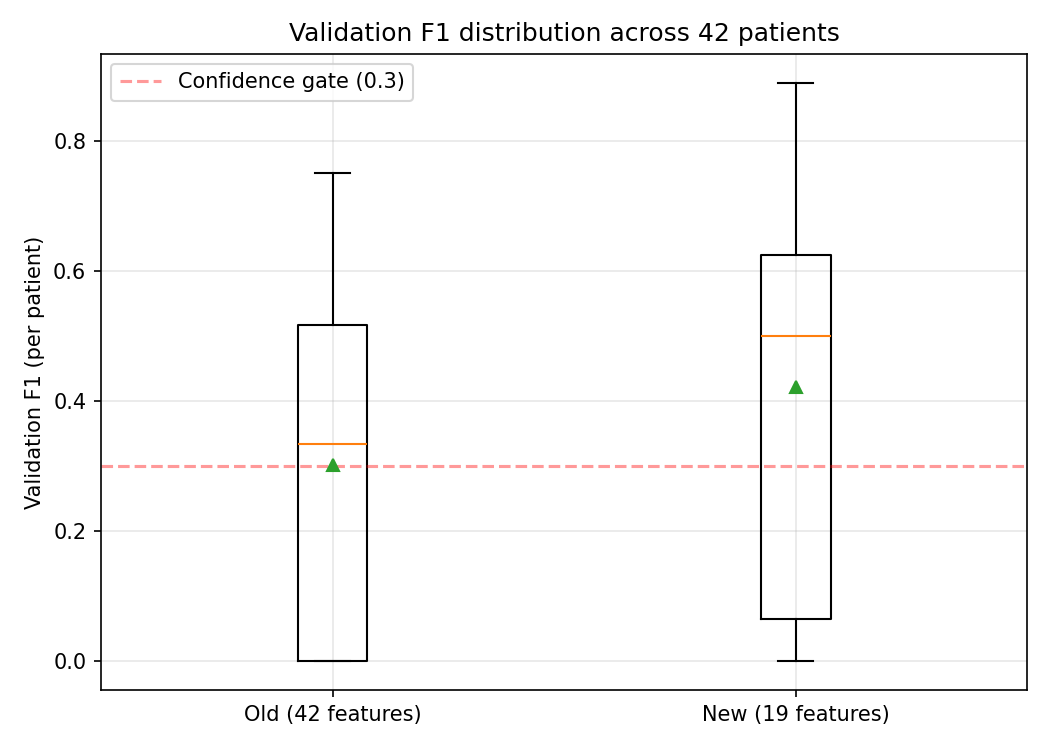
After the cut, we are at roughly 1.1 training examples per feature at the 20-example floor. Still not great by textbook standards, but nearly twice as tractable as before.
We Introduced a Confidence-Weighted Blend
The old system used a binary switch: if the ML model's confidence was high enough and its probability was decisive enough (above 0.7 or below 0.3), use ML; otherwise fall back to the heuristic entirely. That created a cliff where the ML went from 0% contribution to 100% at an arbitrary threshold. Predictions in the 0.3–0.7 range were thrown away.
The new rule: the heuristic is always the anchor, and the ML slides in proportionally to how decisive it is.
mlWeight = |probability − 0.5| × 2
At probability 0.5 (a coin flip), the ML contributes nothing — the heuristic runs the show. At 0.7, the ML contributes 40%. At 0.9, it contributes 80%. The heuristic never gets overruled by an uncertain model.
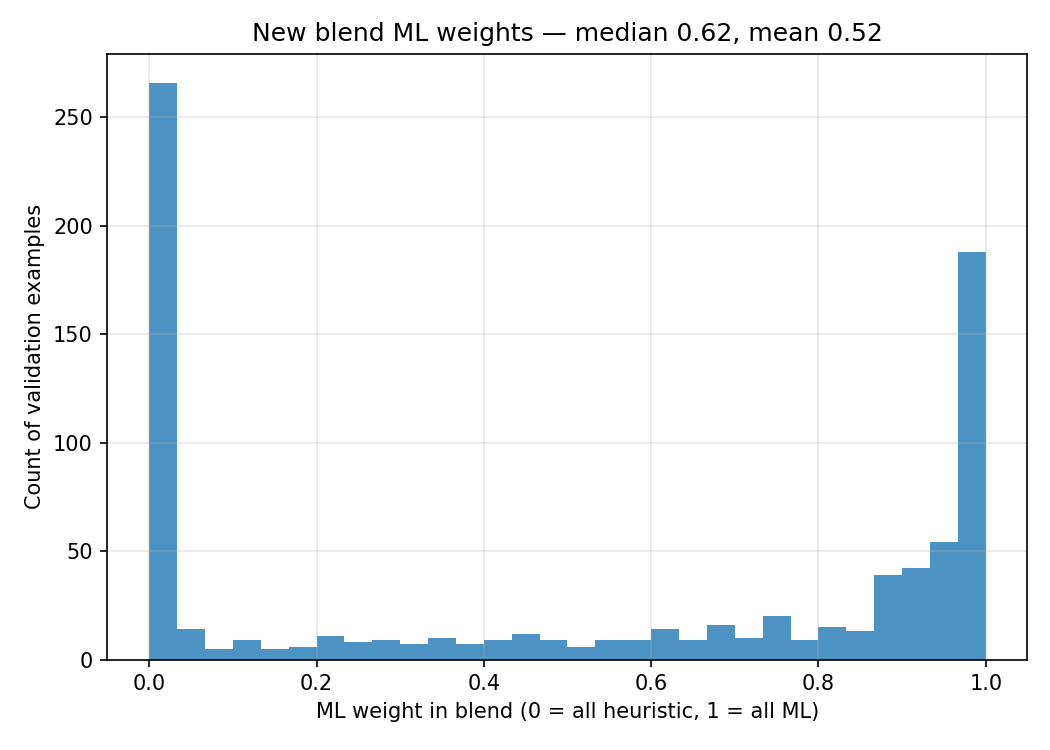
The histogram above shows what this looks like in practice. The U-shape is exactly what we want: most predictions are either near 0 (the model is uncertain, so the heuristic takes over) or near 1 (the model is confident and earns its weight). The blend is not a compromise — it is a mechanism for the ML to prove it has something to say.
Three things this gives us. Safety — the heuristic is clinically grounded and its rules are debuggable. We never let an uncertain ML prediction override it. Gradual trust — as the model gets more data and its validation F1 improves, decisive predictions naturally carry more weight without shipping a new threshold. Nothing wasted — we stopped throwing away the middle band. A 0.65 probability now shows up as a 30% ML signal blended with 70% heuristic, instead of being silently ignored.
What It Looks Like for a Single Patient
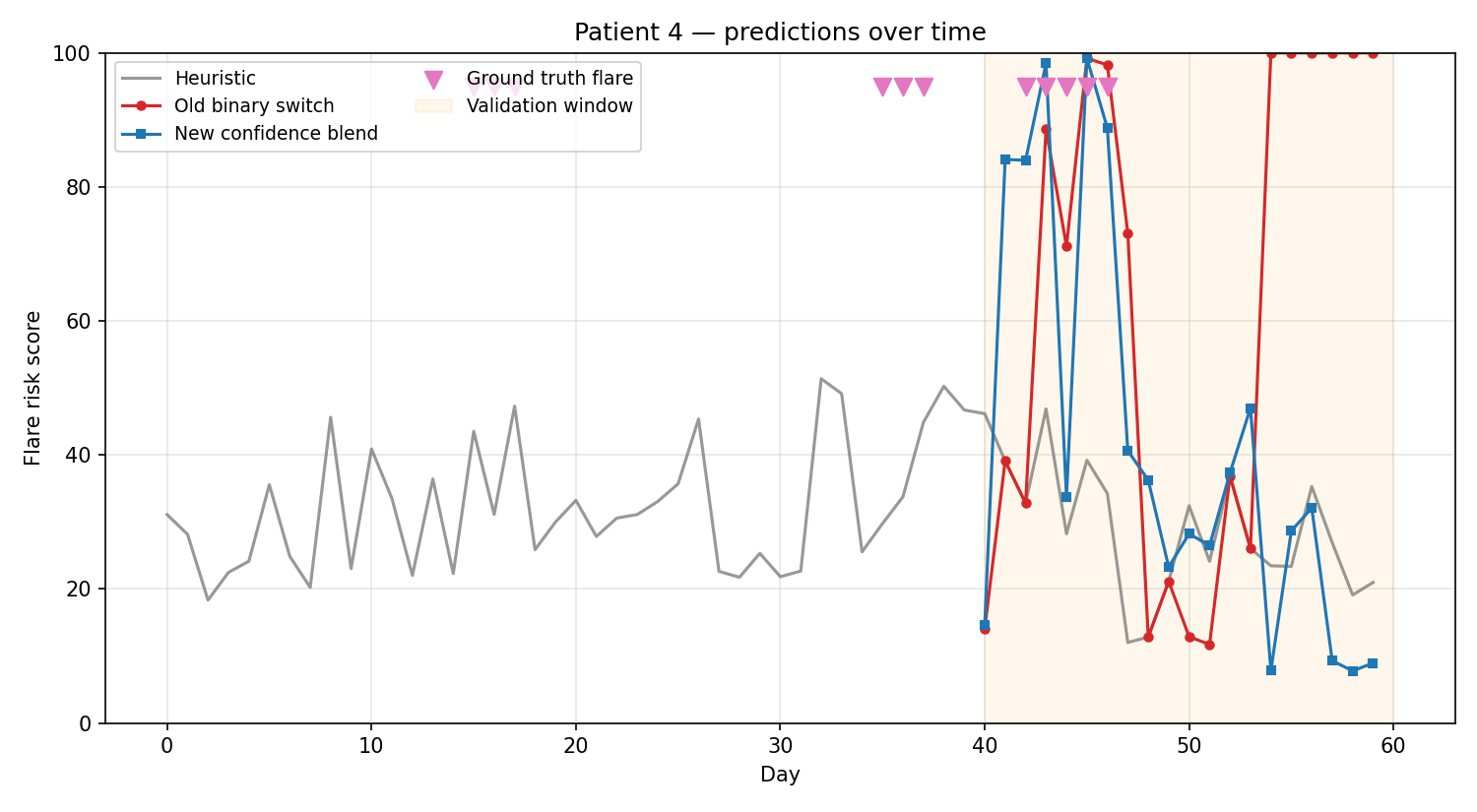
The timeline below shows one patient's predictions over 60 days. The grey line is the heuristic alone. The red line is the old binary switch approach — you can see it jumping erratically as the ML flips between full control and no control. The blue line is the new blended approach — smoother, steadier, and still responsive to actual flare days (marked in pink).
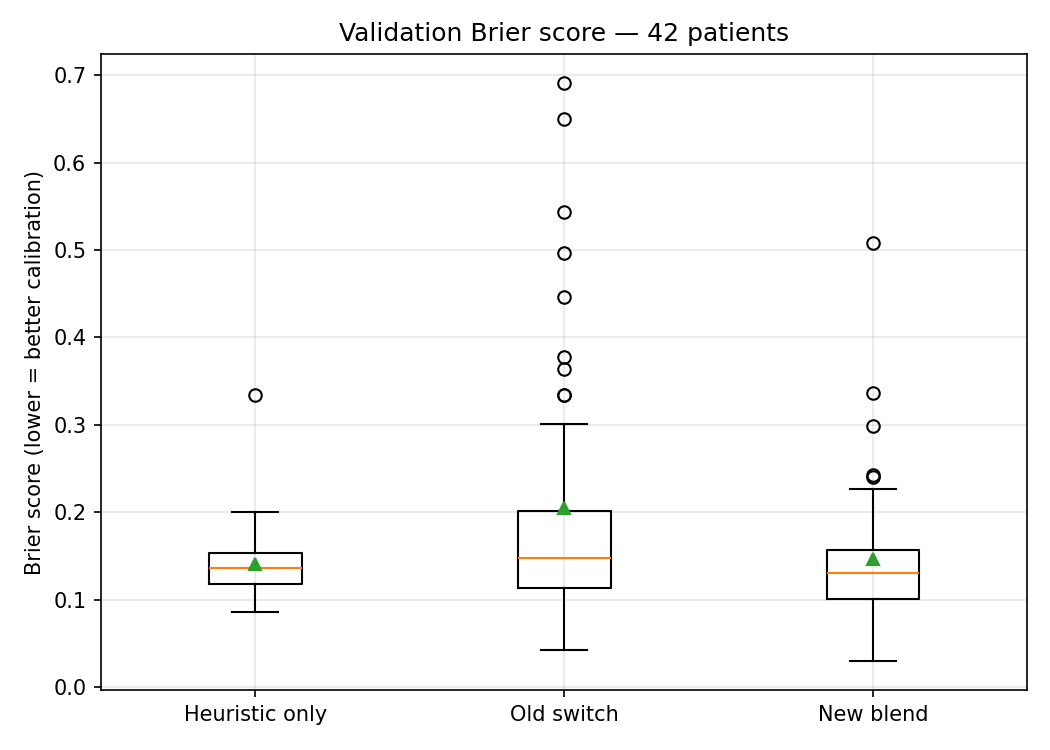
The Brier score comparison across all patients tells the same story quantitatively. The old binary switch had wild variance — some patients got reasonable predictions, others got noise. The new blend is tighter and more consistent.
ML Is Never Ship-and-Forget
If there is one takeaway from this work, it is this: the model you ship today is not the model you should trust tomorrow. Machine learning on personal health data is a continuous process — plot your results, evaluate your parameters, spot where the model is fooling itself, adjust, and repeat. Every honest evaluation cycle makes the next version measurably better.
We run this loop constantly. We plot train vs. validation metrics to catch overfitting. We check calibration curves to see if a "70% flare risk" actually means flares happen 70% of the time. We track Brier scores to measure overall prediction quality. When something looks off, we dig into why — and that digging is how we found the temporal leak and the oversized feature set in the first place.
This is not unique to Lycana. It is how ML should work everywhere, especially in health. A model that is deployed and forgotten will drift, degrade, and eventually mislead. A model that is continuously evaluated will compound its improvements. The gap between the two grows with every cycle you skip.
Lycana's on-device architecture makes this loop particularly important. Each user's model trains on their personal data — there is no centralized dataset to fall back on. That means the model evaluation pipeline has to be rigorous enough to work with 20 examples just as well as 200. The changes we shipped last week are one iteration in that ongoing process. They will not be the last.
The Principle
Treat ML as a player, not the captain. It earns its weight by being decisive; it never gets to overrule the heuristic while it is still uncertain. When a prediction is wrong, we want to know whether it was the ML or the heuristic — and with the blend weight logged on every prediction, we do.
The net result: flare risk predictions during the first month of tracking are noticeably steadier, the model no longer swings wildly between confident-but-wrong answers and heuristic fallbacks, and the validation metrics we trust to gate the ML's weight are finally honest about what they measure.
Lycana is not a medical device and does not provide medical advice. Always consult your healthcare provider for diagnosis and treatment decisions.
Track your symptoms. Predict your flares.
Lycana helps you spot patterns in your lupus journey — privately, on your device.
Get the App